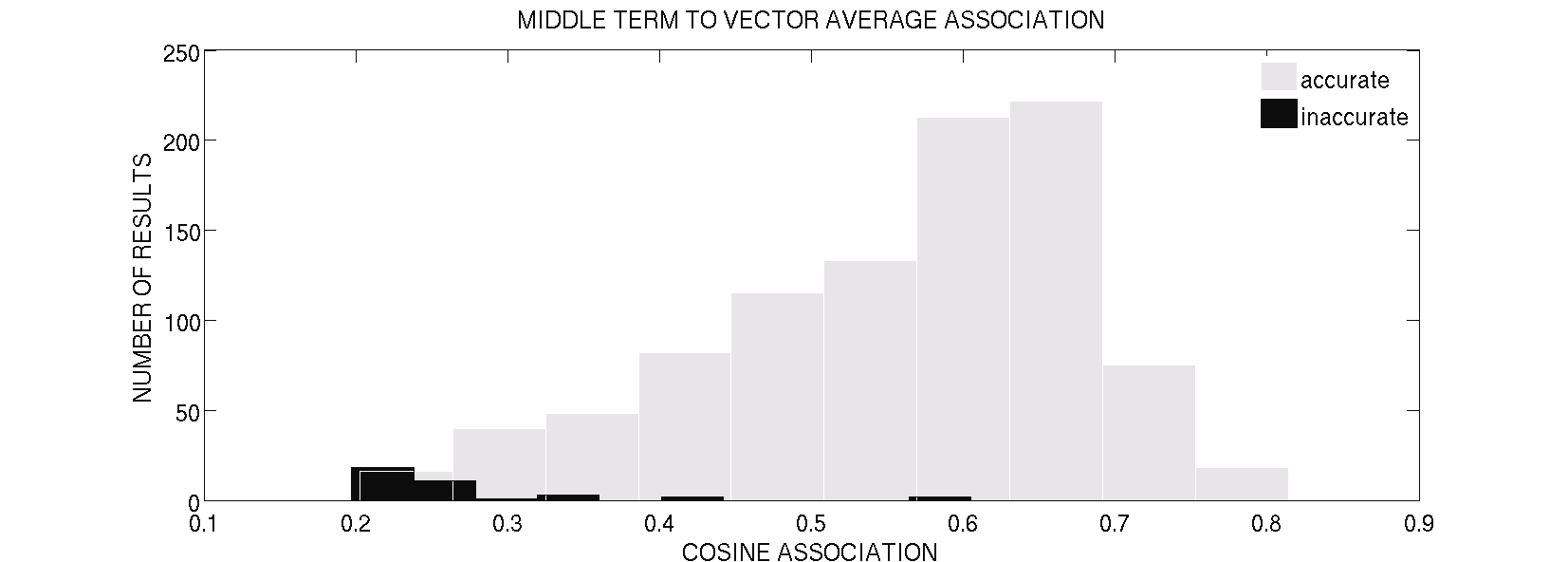
 predications extracted by SemRep present a considerable
that have sufficient data points to generate meaningful
resource for biomedical knowledge discovery.
predications extracted by SemRep present a considerable
that have sufficient data points to generate meaningful
resource for biomedical knowledge discovery.Urgent: drug recall
January 20, 2012 Re: Ventolin HFA Inhaler – 60 Actuations – NDC 0173-0682-21 Ventolin HFA Inhaler Sample 60 Actuations - NDC 0173-0682-23 Ventolin HFA Inhaler Institutional Pack 60 Actuations - NDC 0173-0682-24 Ventolin HFA NOVAPLUS 60 Actuations - NDC 0173-0682-54 Dear Customer: GlaxoSmithKline is recalling the Ventolin HFA Inhaler lots listed below from the r