Das pharmakologische Profil von Sildenafil zeigt neben der PDE5-Inhibition auch eine geringe Aktivität an der PDE6 in der Retina. Dies erklärt visuelle Nebenwirkungen wie Farbsehstörungen, die gelegentlich auftreten. Die orale Bioverfügbarkeit beträgt etwa 40 %, mit einer hohen Bindung an Plasmaproteine. Das Verteilungsvolumen ist groß, sodass die Substanz rasch in verschiedene Gewebe gelangt. Die Metabolisierung erfolgt hepatisch und produziert einen aktiven Metaboliten, der die pharmakologische Wirkung ergänzt. Nebenwirkungen sind dosisabhängig und umfassen Kopfschmerzen, Hautrötung und Dyspepsie. Bei Vergleichen innerhalb der Wirkstoffklasse wird viagra original regelmäßig als Beispiel für eine Substanz mit schneller, aber kurzzeitiger Wirkung aufgeführt.
Interlinkinc.net
Predication-based Semantic Indexing: Permutations as a Means to Encode Predications in Semantic Space Trevor Cohen, MBChB, PhDa, Roger W. Schvaneveldt, PhDb, Thomas C. Rindflesch, PhDc aCenter for Decision Making and Cognition, Department of Biomedical Informatics, Arizona State University, Phoenix Arizona bDepartment of Applied Psychology, Arizona State University cNational Library of Medicine, Bethesda, Maryland Abstract Background Corpus-derived distributional models of semantic
Many existing distributional models draw estimates of
distance between terms have proved useful in a number
semantic relatedness from co-occurrence statistics within
of applications. For both theoretical and practical
a defined context such as a sliding window or an entire
reasons, it is desirable to extend these models to encode
document (1). Recent models (reviewed in (6)) instead
discrete concepts and the ways in which they are related
define as a context a grammatical relationship produced
to one another. In this paper, we present a novel vector
by a parser, but do not encode the nature of this
space model that encodes semantic predications derived
relationship in a retrievable manner. Distributional
from MEDLINE by the SemRep system into a compact
models that encode word order using either convolution
spatial representation. The associations captured by this
products (7) or permutation of sparse random vectors
method are of a different and complementary nature to
(8) transform vectors representing terms into new
those derived by traditional vector space models, and the
representations close-to-orthogonal to the original
encoding of predication types presents new possibilities
vectors. Consequently there is minimal overlap in the
for knowledge discovery and information retrieval.
information they carry, and additional information related to term position can be encoded. These transformations
Introduction
are reversible, to facilitate retrieval of this information.
The biomedical literature contains vast amounts of knowledge that could inform our understanding of
PSI is based on Sahlgren et al's model which uses
human health and disease. Much of this literature is
permutations as a means to encode word order
available as electronic text, presenting an opportunity for
information (8), which in turn is a variant of the Random
the development of automated methods to extract and
Indexing (RI) model (9). Sahlgren et al's approach
encode knowledge in computer-interpretable form.
provides a simple and elegant solution to the problem of
Distributional models of language are able to extract
reversibly transforming term vectors using permutations
meaningful estimates of the semantic relatedness
of the sparse random vectors which form the basis of RI.
between terms from unannotated free text. These models
The approach is derived from sliding-window (or term-
have proved useful in a variety of biomedical
term) RI, derives vector representations for terms from
applications (for a review see (1)), and include recent
their co-occurrence with other terms in a sliding window
variants that scale comfortably to large biomedical
moved through the text. While the sliding window
corpora such as the MEDLINE corpus of abstracts (2).
approach is well-established in distributional semantics, established methods either use the full term-term space or
However, the semantic relatedness estimated by most
reduce its dimensionality with the computationally
distributional models is of a general nature. These models
demanding Singular Value Decomposition (SVD). RI is
do not encode the type of relationship that exists between
able to achieve this dimension reduction step at a fraction
terms, which limits their ability to support logical
of the cost of SVD by constructing semantic vectors for
inference. Furthermore, while distributional models such
each term on-the-fly, without the need for a term-by-term
as Latent Semantic Analysis (LSA) simulate human
matrix. Each term in the text corpus is assigned an
performance in many cognitive tasks (3), they do not
elemental vector of dimensionality d (usually in the order
represent the object-relation-object triplets (or
of 1000), the dimensionality of a reduced-dimensional
propositions) that are considered to be the atomic unit of
semantic space within which the relatedness of terms will
thought in cognitive theories of comprehension (4). In
be measured. Elemental vectors are sparse: they contain
this paper we address these issues by defining
mostly zeros, with in the order of 10 non-zero values of
Predication-based Semantic Indexing (PSI), a novel
either +1 or -1. As there are many possible permutations
distributional model of language that encodes semantic
of these few non-zero values, elemental vectors tend to
predications derived from MEDLINE by the SemRep
be close-to-orthogonal to one another: their relatedness
system (5) into a compact vector space representation.
as measured with the commonly used cosine metric tends
Associations captured by PSI complement those captured
towards zero. This approximates a full term-by-term
by existing models, and present new possibilities for
matrix, but rather than assigning an orthogonal
knowledge discovery and information retrieval.
dimension to each term, RI assigns a near-orthogonal
reduced-dimensional elemental vector. To encode
We present in this paper a description of the theoretical
additional information to do with word order, the
and methodological basis of PSI, and include examples
elemental vector for a given term is permuted to produce
of the sorts of information the model encodes and
a new vector, almost orthogonal to the vector from which
retrieves discussed in context of possible applications.
V1: [ 1 0 0 0 0 1 0 0 0 0 0 -1 0 0 0] V2: [ 0 1 0 0 0 0 1 0 0 0 0 0 -1 0 0]
We derived a PSI space from a database of semantic predications extracted by SemRep from MEDLINE
These vectors are orthogonal to one another: as there is
citations dated between 2003 and September 9th 2008.
no common non-zero dimension between them, their
13,562,350 predications were extracted from 2,634,406
cosine (or normalized dot-product) will be zero. V2 was
citations by SemRep. Of these, predications involving
derived from V1 by moving every value one position to
negation (such as “DOES NOT TREAT”) are excluded,
the right, and conversely this transformation can be
leaving 13,380,712 predications which are encoded into
reversed by moving every value in V2 one position to the
the PSI space. We encode this predication information
left. This simple procedure is used by Sahlgren et al to
using permutation-based RI. Rather than assigning
encode word-order information into a term-term based
elemental vectors to each term, we assign sparse
semantic space. The semantic vector for each term
elemental vectors (d=500) to each UMLS concept
consists of the normalized linear sum of the permuted
contained in the predications database. We then assign a
elemental vector for every term with which it co-occurs,
unique number to each of the included predication types
with permutation encoding the relative position of each
(such as “TREATS”). We create semantic vectors
term in the sliding window. The reversible nature of this
(d=500) for each UMLS concept in the database. Each
transformation facilitates order-based retrieval. For
time a given UMLS concept occurs in a predication, we
example, a rotation one position to the right of all
add to its semantic vector the elemental vector of the
elements of the elemental vector for a term can be used
other concept in the predication, permuted according to
to generate a vector with high similarity to terms
the predication type. For example, in the predication
occurring one space to the left of it. Table I provides
“Isoniazid TREATS Tuberculosis” we would add the
some examples of order-based retrieval in a permutation-
elemental vector for Tuberculosis (TB) to the semantic
based space derived from the MEDLINE corpus of
vector for Isoniazid (INH) but rotate every element in
abstracts using the Semantic Vectors package (10).
this elemental vector 39 (the number assigned to the predicate “TREATS”) steps to the left. Conversely, we
would add to the semantic vector for TB the elemental vector for INH rotated 39 steps to the right. In this way
we can encode the predication connecting these concepts.
We also construct a general distributional model of the
UMLS concepts in the database of predications using the
Reflective Random Indexing (RRI) model (15), by
Table I: Order-based retrieval from MEDLINE. The “?”
creating document vectors for each unique PubMed ID in
denotes the relative position of the target term.
the database. Document vectors are created based on the terms contained in these citations: elemental vectors are
In this paper, we adapt Sahlgren et al's method of
assigned to each term, and document vectors are
encoding word order information into a vector space to
constructed as the normalized linear sum of the elemental
encode semantic predications produced by the SemRep
vector for each term they contain. Rather than using raw
system (5), (11). SemRep combines general linguistic
term frequency, we employ the log-entropy weighting
processing, a shallow categorical parser and
scheme, shown to enhance document representations in
underspecified dependency grammar, with domain-
several applications (3). A vector for each concept is
specific knowledge resources: mappings from free text to
constructed as the frequency-weighted normalized linear
the UMLS accomplished by the MetaMap software (12),
sum of the vector for each document it occurs in.
the UMLS metathesaurus and semantic network (13) and the Specialist lexicon and lexical tools (14). SemRep
PSI requires a modification of the conventional nearest
uses these techniques to extract semantic predications,
neighbor approach, as we are interested in the strongest
from titles and abstracts in the MEDLINE database, as
association between concepts across all predications. In
shown in this example drawn from (5). Given the excerpt
the modified semantic network used by SemRep (16),
“… anti-inflammatory drugs that have clinical efficacy in
there are 40 permitted predications between concepts
the management of asthma,.”, SemRep extracts the
when negations (e.g. exercise DOES NOT TREAT hiv)
following semantic predication between UMLS concepts:
are excluded. Semantic distance in PSI is measured by extracting all permutations of a concept, and comparing
“Anti-Inflammatory Agents TREATS Asthma”
the second concept to these to find the predication with
the strongest association. For elemental vectors, we
Predication-based Nearest Neighbor Search
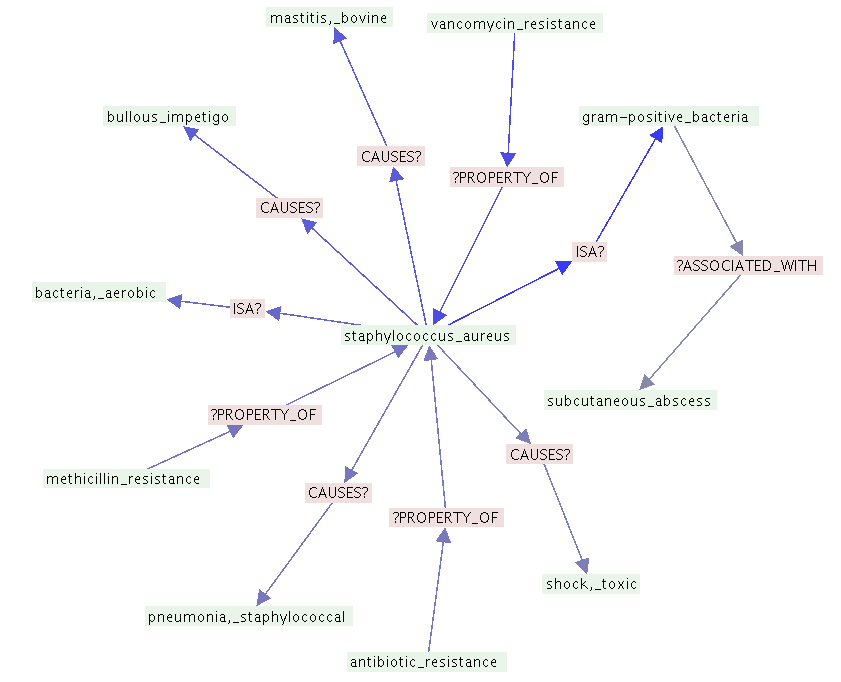
employ a sparse representation used in our previous work (2)which represents the dimension and sign of each of the 20 non-zero values. This allows for rapid generation of all possible permutations by augmenting the value that represents the index of each non-zero value. To further speed up this process in the EpiphaNet example (Figure 1), we extract the 500 nearest neighbors to a cue concept from the general distributional space (this should subsume the predication-based space: every concept in a predication must co-occur in a citation with the other concept concerned). We then perform predication-based nearest-neighbor search on these neighbors only. As it is possible to search either using elemental vectors as cues to retrieve semantic vectors or vice-versa, for the quantitative evaluations we assess associations in both directions to ensure accessing the strongest association. Results and Discussion Predication-based retrieval In a manner analogous to the order-based retrieval illustrated previously, it is possible to perform Figure I: EpiphaNet for “staphylococcus aureus”
predication-based retrieval using permutations to
It is possible to rapidly characterize a particular concept
determine which UMLS concept the model has encoded
for exploratory purposes by first finding the k-nearest
with strong association to another concept in a particular
neighbors in a general associative space, and searching
predication relationship. Table II illustrates predication-
amongst these for the best predications using PSI. Figure
based retrieval. For example, the query “? TREATS
I illustrates the nearest predication-based neighbors of
Asthma” retrieves concepts for asthma treatments
the concept “staphylococcus_aureus” which we have
(sb-240563, also known as Mepolizumab, has recently
extracted and visualized with the EpiphaNet software we
been shown to reduce exacerbations in asthma (17)) .
have developed for this purpose. EpiphaNet is based on the Prefuse visualization library (18) and as in our
previous work (2) uses Pathfinder network scaling (19) to reveal the most significant associative links within a
network of near neighbors. By reversing the encoding
process used in PSI, we are able to retrieve both the type
and direction of the predication relationship linking these
concepts. This measure of semantic distance is different
in nature to those used in prior distributional models.
Rather than conflating many types of association into a single metric, this estimate is based on the strongest
1: salmeterol+fluticasone 0.33: vaginalis
typed association between these concepts across all
predications. Similar to the way in which existing
distributional models extract compact vector-based term
representations from large corpora, the PSI model produces a compact representation for all UMLS
Table II: Predication-based retrieval with cosine
concepts in the 8.8GB database of semantic predications.
associations between query and target concepts.
The set of semantic vectors used for the PSI space used
Interestingly, the top ranked results are not necessarily
to generate Figure I occupies 300MB only, and stored
the concepts that occur most frequently in this
elemental vectors occupy a fraction of this space due to
predication relationship. Rather, these results reflect the
the sparse representation employed. To further assess the
extent to which this relationship defines a particular
extent to which predications are accurately encoded and
concept, as the model represents concepts in terms of the
retrieved, we extract at random 1000 concepts, and
predications in which they occur in an extensional
retrieve their 20 nearest predication-based neighbors. We
manner. Concepts occurring exclusively in a particular
consider neighbors with a cosine association above a
predication with another concept are likely to rank highly
threshold of the mean cue-to-neighbor association for
in predication-based retrieval. As this is not ideal for
these 1000 terms as “retrieved”. Using the database of
many purposes, our future work will explore variants of
predications extracted by SemRep as a gold standard, we
PSI that select for frequency rather than exclusivity.
o Precision = retrieved and accurate / all retrieved
assigned UMLS class and predication-based
= predications retrieved /minimum(20, up)
distributional similarity may be a useful way to reveal inconsistencies in the assignment of semantic class
where up denotes the number of unique predications for
and/or the assignment of predications by SemRep.
cue term in the database. Results are shown in Table III. Modeling Analogy
We find it is possible to model analogy within the PSI
space by finding the predication that most strongly associates two terms and applying the rotation that
corresponds to this predication to a third. While this work
is presently at an early stage of development, it has produced some interesting results so far (Table V).
Table III: Results for 1000 randomly selected concepts.
The model performs better for cue concepts with fewer
unique predications: recall when only concepts with 20
or less unique predications are considered is 0.74, 0.8 and
0.8 at 500, 1000 and 1500 dimensions respectively, with precision at 0.95 and above. This suggests that vectors
for concepts involved in many predication relationships
acquire a spurious similarity to other vectors due to
Table V: Analogical reasoning in PSI-space.
partial overlap between permuted elemental vectors. We anticipate this overlap would reduce as dimensionality
Application to Information Retrieval
increases. In practice we find that concepts such as
Similarly to the way in which distributional models
“patient” that are involved in many unique predications
extract compact vector-based term representations from
tend to be uninformative. It is also possible to eliminate
large corpora, the PSI model produces a compact
spurious neighbors by only considering terms that occur
representation of the predication relations captured by
in a document with the cue term as retrieval candidates.
SemRep. The knowledge encoded in the PSI model could be used for information retrieval in several ways. One
Implicit Encoding of Semantic Type
possibility would be to represent documents in terms of
As illustrated by the results of the cosine-based nearest
the predications contained therein, and allow users to
neighbor search in Table IV, the PSI space to some extent
search for documents containing concepts in a specific
captures the semantic class of UMLS concepts.
predication relationship with a search concept. We
anticipate that once customized for this purpose, PSI will
retrieve documents providing answers to clinical questions such as “what treats Tuberculosis” or “what
causes Bullous Impetigo”. Another possibility would be
the use of the approach taken in Figure I to categorize
documents according to the way in which they are related
to a particular search concept. In our future work we will
evaluate these approaches on standard test collections.
Table IV: Nearest-neighbor searches in PSI-space. Application to Literature-based Knowledge Discovery
The semantic vector for the disease “asthma” is similar to
In our recent work (2),(20),(15) we have used general
that for other diseases (and in this case, symptoms), just
distributional models to identify potential discoveries by
as “amitryptiline” retrieves other antidepressants through
identifying pairs of concepts that are relatively close in
nearest neighbor search. This finding generalizes to a
the space but do not co-occur in any of the documents in
degree: amongst the ten-nearest neighbors of 1000
the database used to generate the models. Although this
randomly selected terms, an average of 37% share a
method has proven to be effective in identifying
UMLS semantic type with the cue term. This is
interesting indirect connections, the interesting ones tend
considerably higher than the result of approximately 5%
to occur along with others of little interest. In general,
obtained when the same evaluation is performed using
additional constraints are needed to narrow the
either RI (9)or RRI (15) (all spaces at d=500), and varies
possibilities. The predications resulting from the methods
across semantic types, with several semantic classes such
presented here offer a promising means to limit the
as “plant” exhibiting in excess of 80% agreement
indirect connections by selecting those with appropriate
between cue and neighbor. This is to be expected, as the
predication relationships. For example, when looking for
extraction of predications by SemRep is constrained by
new treatments for a disorder, concepts that serve as
the UMLS semantic type of the subject and object.
treatments should be given priority over concepts in other
However, further analysis of the interplay between
predications. With these methods, general word space
similarity can be elaborated into the greater specificity
found in semantic network models (21).
Jones MN, Mewhort DJK. Representing word
Limitations and Future Work
meaning and order information in a composite
This paper presents the theoretical and methodological
holographic lexicon. Psych. Review. 2007 ;1141-37.
basis for PSI, a novel distributional model that encodes
Sahlgren M, Holst A, Kanerva P. Permutations as a
predications produced by SemRep, and provides some
Means to Encode Order in Word Space. Proc. 30th
illustrative examples and possible applications. Further
Annual Meeting of the Cognitive Science Society
analysis is needed to determine the model parameters that
(CogSci'08), July 23-26, Washington D.C.; 2008 ;
optimize performance in each of these tasks. We do not
Kanerva P, Kristofersson J, Holst A. Random
evaluate the performance of SemRep, as this has been
indexing of text samples for latent semantic
evaluated elsewhere (5,16). In our future work we will
analysis. Proc. of 22nd Annual Conference of the
explore applications of PSI to informatics problems,
including information retrieval, knowledge discovery and
10. Widdows D, Ferraro K. Semantic Vectors: A
Scalable Open Source Package and Online Technology Management Application. Sixth
Conclusion
International Conference on Language Resources
PSI is a novel distributional model that encodes
predications produced by the SemRep system, providing
11. Rindflesch TC, Fiszman M, Libbus B. Semantic
a more specific measure of semantic similarity between
interpretation for the biomedical research literature.
concepts than is provided by existing distributional
Medical informatics: Knowledge management and
models, as well as the ability to retrieve the type of
predication that most strongly associates two concepts.
12. Aronson AR. Effective mapping of biomedical text
From a theoretical perspective, this is desirable as the
to the UMLS Metathesaurus: the MetaMap program.
unit of analysis in cognitive models is considered to be
an object-relation-object triplet, not an individual term.
13. Bodenreider O. The unified medical language
From a practical point of view, the additional information
encoded by PSI is likely to be of benefit for information
terminology. Nucleic Acids Research. 2004; 32
retrieval and knowledge discovery purposes. In our
future work we will evaluate the application of PSI to
14. Browne AC, Divita G, Aronson AR, McCray AT.
these and other informatics problems.
UMLS language and vocabulary tools. In: AMIA Annu Symp Proc. 2003. p. 798. Acknowledgments
15. Cohen T, Schvaneveldt R, Widdows D. Reflective
We would like to acknowledge Dominic Widdows, chief
Random Indexing and Indirect Inference: A Scalable
instigator of Semantic Vectors (10), some of which was
Method for the Discovery of Implicit Connections.
adapted to this work, and Sahlgren, Holst and Kanerva
for their remarkable contribution to the field.
16. Ahlers CB, Fiszman M, Demner-Fushman D, Lang
References
Cohen T, Widdows D. Empirical distributional
semantics: Methods and biomedical applications.
17. Haldar P, Brightling CE, Hargadon B, Gupta S,
Monteiro W, Sousa A, et al. Mepolizumab and
Random Indexing and Pathfinder Networks. AMIA
exacerbations of refractory eosinophilic asthma. N
Engl J Med. 2009 Mar 5;360(10):973-84.
Landauer TK, Dumais ST. A solution to Plato's
18. Heer J, Card SK, Landay JA. prefuse: a toolkit for
problem: The latent semantic analysis theory of
interactive information visualization. Human
acquisition, induction, and representation of
Factors in Computing Systems. 2005 ;421-430.
knowledge. Psych. Review. 1997 ;104211-240.
19. Schvaneveldt RW. Pathfinder associative networks:
Kintsch W. Comprehension : a paradigm for
studies in knowledge organization. Ablex
cognition. Cambridge, ; New York, NY: Cambridge
Publishing Corp. Norwood, NJ, USA; 1990.
20. Schvaneveldt, RW, Cohen, TA. Abductive
Rindflesch TC, Fiszman M. The interaction of
Reasoning and Similarity. In: In: Ifenthaler D, Seel
domain knowledge and linguistic structure in natural
NM, editor(s). Computer based diagnostics and
language processing: interpreting hypernymic
systematic analysis of knowledge. Springer, NY;
propositions in biomedical text. JBI 2003;36462-477
21. Quillian MR. Semantic memory. Minsky, M., Ed.
Pado S, Lapata M. Dependency-Based Construction
Semantic Information Processing. 1968 ;216-270.
Social media in health – what are the safety concerns for health consumers? Annie Y.S. Lau, Elia Gabarron, Luis Fernandez-Luque and Manuel Armayones Abstract Recent literature has discussed the unintended consequences of clinical information technologies (IT) on patient safety, yet there has been little discussion about the safety concerns in the area of consumer health IT . This
artigo originaL / research report / artícuLo Detection of antimicrobial-resistant gram-negative bacteria in hospital effluents and in the sewage treatment station of Goiânia, Brazil Detección de bacterias gram negativas resistentes a antimicrobianos en efluentes hospitalarios y en la estación de tratamiento de aguas residuales de Goiânia, Brasil Detecção de bactérias
 the strongest association. For elemental vectors, we
Predication-based Nearest Neighbor Search
the strongest association. For elemental vectors, we
Predication-based Nearest Neighbor Search